

Introduction
The bin packing problem is a classic optimization challenge that has far-reaching implications for enterprise organizations across industries. At its core, the problem focuses on finding the most efficient way to pack a set of objects into a finite number of containers or “bins”, with the goal of minimizing wasted space.
This challenge is pervasive in real-world applications, from optimizing shipping and logistics to efficiently allocating resources in data centers and cloud computing environments. With organizations often dealing with large numbers of items and containers, finding optimal packing solutions can lead to significant cost savings and operational efficiencies.
For a leading $10B industrial equipment manufacturer, bin packing is an integral part of their supply chain. It is common for this company to send containers to vendors to fill with purchased parts that are then used in the manufacturing process of heavy equipment and vehicles. With the increasing complexity of supply chains and variable production targets, the packaging engineering team needed to ensure assembly lines have the right number of parts available while efficiently using space.
For example, an assembly line needs sufficient steel bolts on-hand so production never slows, but it is a waste of factory floor space to have a shipping container full of them when only a few dozen are needed per day. The first step in solving this problem is bin packing, or modeling how thousands of parts fit in all the possible containers, so engineers can then automate the process of container selection for improved productivity.
| Challenge ❗Wasted space in packaging containers ❗Excessive truck loading & carbon footprint |
Objective ✅ Minimize empty space in packaging container ✅ Maximize truck loading capacity to reduce carbon footprint |
|---|---|
 |
 |
Technical Challenges
While the bin packing problem has been extensively studied in an academic setting, efficiently simulating and solving it across complex real-world datasets and at scale has remained a challenge for many organizations.
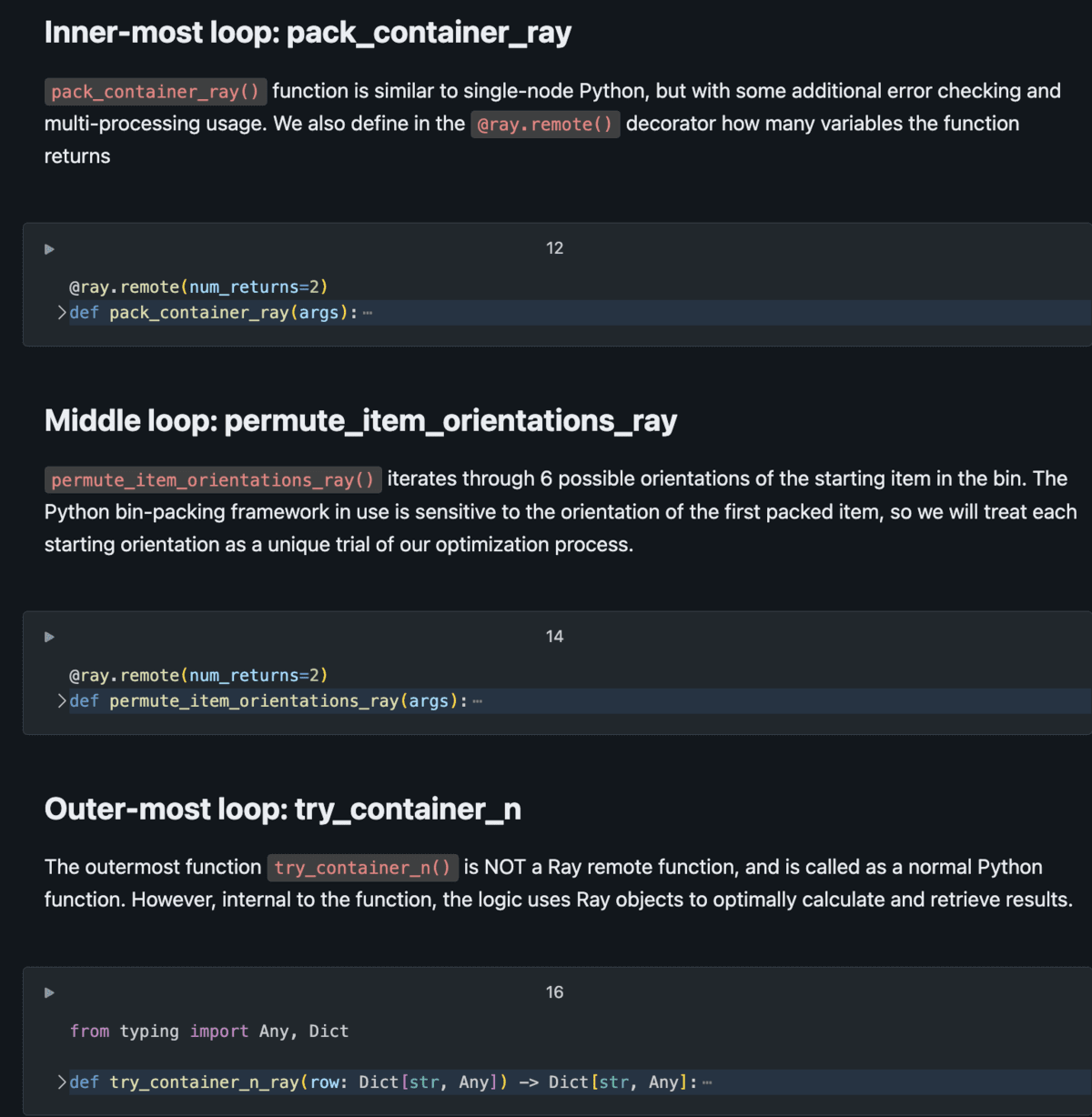
In some sense, this problem is simple enough for anyone to understand: put things in a box until full. But as with most big data problems, challenges arise because of the sheer scale of the computations to be performed. For this Databricks customer’s bin packing simulation, we can use a simple mental model for the optimization task. Using pseudocode:
For (i in items): The process needs to run for every item in inventory (~1,000’s)
↳ For (c in containers): Try the fit for every type of container (~10’s)
↳ For (o in orientations): The starting orientations of the first item must each be modeled (==6)
↳ Pack_container Finally, try filling a container with items with a starting orientationWhat if we were to run this looping process sequentially using single-node Python? If we have millions of iterations (e.g. 20,000 items x 20 containers x 6 starting orientations = 2.4M combinations), this could take hundreds of hours to compute (e.g. 2.4M combinations x 1 second each / 3600 seconds per hour = ~660 hours = 27 days). Waiting for nearly a month for these results, which are themselves an input to a later modeling step, is untenable: we must come up with a more efficient way to compute rather than a serial/sequential process.
Scientific Computing With Ray
As a computing platform, Databricks has always provided support for these scientific computing use-cases, but scaling them poses a challenge: most optimization and simulation libraries are written assuming a single-node processing environment, and scaling them with Spark requires experience with tools such as Pandas UDFs.
With Ray’s general availability on Databricks in early 2024, customers have a new tool in their scientific computing toolbox to scale complex optimization problems. While also supporting advanced AI capabilities like reinforcement learning and distributed ML, this blog focuses on Ray Core to enhance custom Python workflows that require nesting, complex orchestration, and communication between tasks.
Modeling a Bin Packing Problem
To effectively use Ray to scale scientific computing, the problem must be logically parallelizable. That is, if you can model a problem as a series of concurrent simulations or trials to run, Ray can help scale it. Bin packing is a great fit for this, as one can test different items in different containers in different orientations all at the same time. With Ray, this bin packing problem can be modeled as a set of nested remote functions, allowing thousands of concurrent trials to run simultaneously, with the degree of parallelism limited by the number of cores in a cluster.
The diagram below demonstrates the basic setup of this modeling problem.

The Python script consists of nested tasks, where outer tasks call the inner tasks multiple times per iteration. Using remote tasks (instead of normal Python functions), we have the ability to massively distribute these tasks across the cluster with Ray Core managing the execution graph and returning results efficiently. See the Databricks Solution Accelerator scientific-computing-ray-on-spark for full implementation details.
Performance & Results
With the techniques described in this blog and demonstrated in the associated Github repo, this customer was able to:
- Reduce container selection time: The adoption of the 3D bin packing algorithm marks a significant advancement, offering a solution that is not only more accurate but also considerably faster, reducing the time required for container selection by a factor of 40x as compared to legacy processes.
- Scale the process linearly: with Ray, the time to finish the modeling process can be linearly scaled with the number of cores in our cluster. Taking the example with 2.4 million combinations from the top (that would have taken 660 hours to complete on a single thread): if we want the process to run overnight in 12 hours, we need: 2.4M / (12hr x 3600sec) = 56 cores; to complete in 3 hours, we would need 220 cores. On Databricks, this is easily controlled via a cluster configuration.
- Significantly reduce code complexity: Ray streamlines code complexity, offering a more intuitive alternative to the original optimization task built with Python’s multiprocessing and threading libraries. The previous implementation required intricate knowledge of these libraries due to nested logic structures. In contrast, Ray’s approach simplifies the codebase, making it more accessible to data team members. The resulting code is not only easier to comprehend but also aligns more closely with idiomatic Python practices, enhancing overall maintainability and efficiency.
Extensibility for Scientific Computing
The combination of automation, batch processing, and optimized container selection has led to measurable improvements for this industrial manufacturer, including a significant reduction in shipping and packaging costs, and a dramatic increase in process efficiency. With the bin packing problem handled, data team members are moving on to other domains of scientific computing for their business, including optimization and linear-programming focused challenges. The capabilities provided by the Databricks Lakehouse platform offer an opportunity to not only model new business problems for the first time, but also dramatically improve legacy scientific computing techniques that have been in use for years.
In tandem with Spark, the de facto standard for data parallel tasks, Ray can help make any “logic-parallel” problem more efficient. Modeling processes that are purely dependent on the amount of compute available are a powerful tool for businesses to create data-driven businesses.
See the Databricks Solution Accelerator scientific-computing-ray-on-spark.

{kind=link}