

Retrieval-Augmented Generation (RAG) systems enhance generative AI capabilities by integrating external document retrieval to produce contextually rich responses. With the release of GPT 4.1, characterized by exceptional instruction-following, coding excellence, long-context support (up to 1 million tokens), and notable affordability, building agentic RAG systems becomes more powerful, efficient, and accessible. In this article, we’ll discover what makes GPT-4.1 so powerful and learn how to build an agentic RAG system using GPT-4.1 mini.
Overview of GPT 4.1
GPT 4.1 significantly improves upon its predecessors, providing substantial gains in:
- Coding: Achieves a 55% success rate on SWE-bench Verified, significantly outperforming GPT 4o.
- Instruction Following: Enhanced capabilities to handle complex, multi-step, and nuanced instructions effectively.
- Long Context: Supports a context window of up to 1 million tokens, suitable for broad data analysis. However, retrieval accuracy slightly decreases with extended contexts.
- Cost Efficiency: GPT-4.1 offers 83% lower costs and 50% reduced latency compared to GPT-4o.
What’s New in GPT 4.1?
OpenAI has rolled out the GPT-4.1 lineup, including three models: GPT-4.1, GPT-4.1 Mini, and GPT-4.1 Nano. Here is what it offers:
1. 1M Token Context: Think Bigger Prompts
One of the headline features is the 1-million-token context window – a first for OpenAI. You can now feed in massive blocks of code, research papers, or entire document sets in one go. That said, while it handles scale impressively, pinpoint accuracy fades as the input grows, so it’s best used for broad context understanding rather than surgical precision.
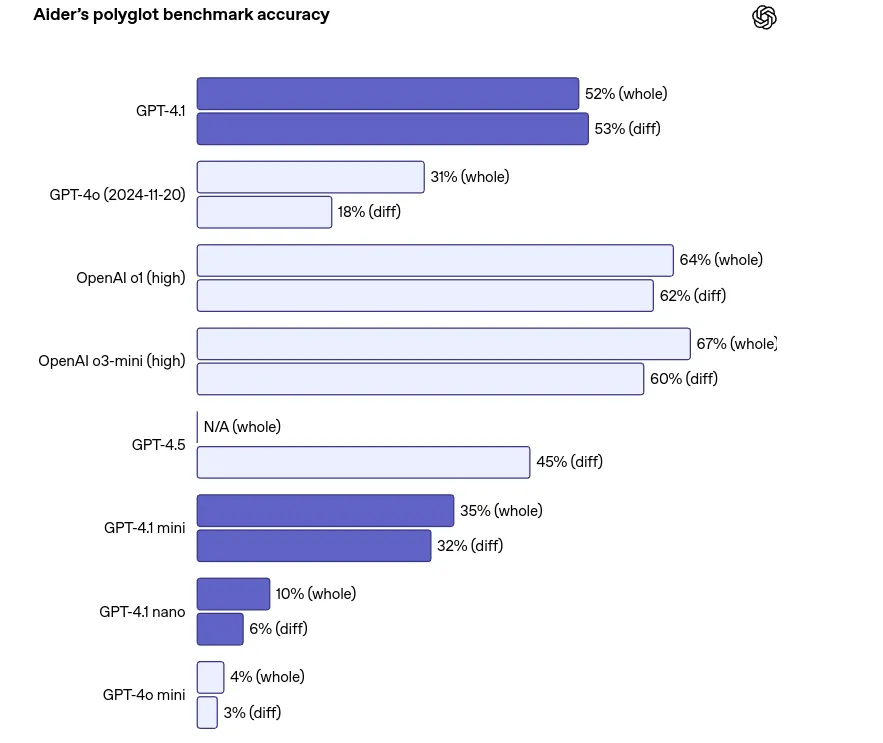
2. Coding Upgrades: Smarter, Multilingual, More Accurate

When it comes to programming, GPT-4.1 steps up significantly:
- Python Benchmarks: It scores 55% on SWE-bench verified, outdoing GPT-4o.
- Multilingual Code Tasks: Thanks to the Polyglot benchmark, it can handle multiple languages better than before.
- Ideal for auto-generating code, debugging, or even assisting in full-stack builds.
3. Better Instruction Following
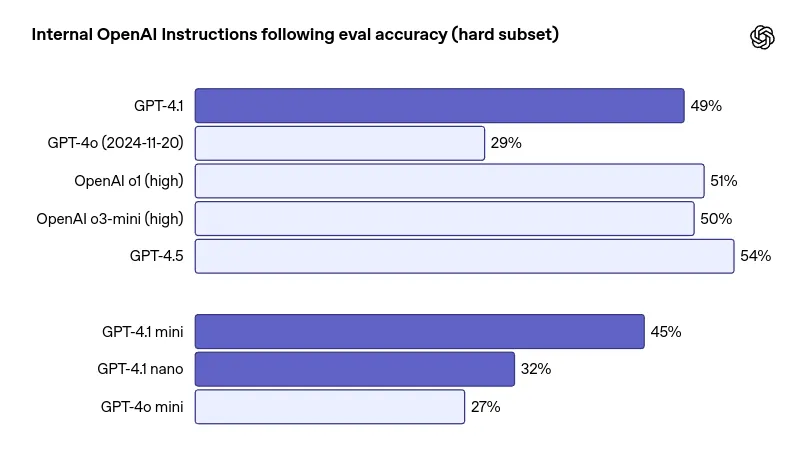
GPT-4.1 is now more responsive to multi-step instructions and nuanced formatting rules. Whether you’re designing workflows or building AI agents, this model is much better at doing what you actually ask for.
4. Speed & Cost: Half the Latency, Fraction of the Price
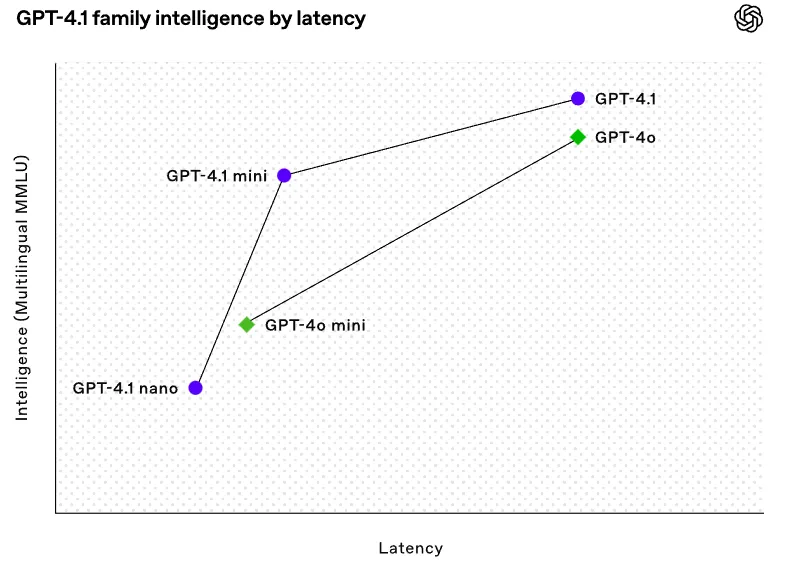
This version is optimized for performance and affordability:
- 50% faster response times
- 83% cheaper than GPT-4o
- The Nano variant is particularly geared for high-frequency, budget-sensitive use – perfect for scaling applications with tight margins.
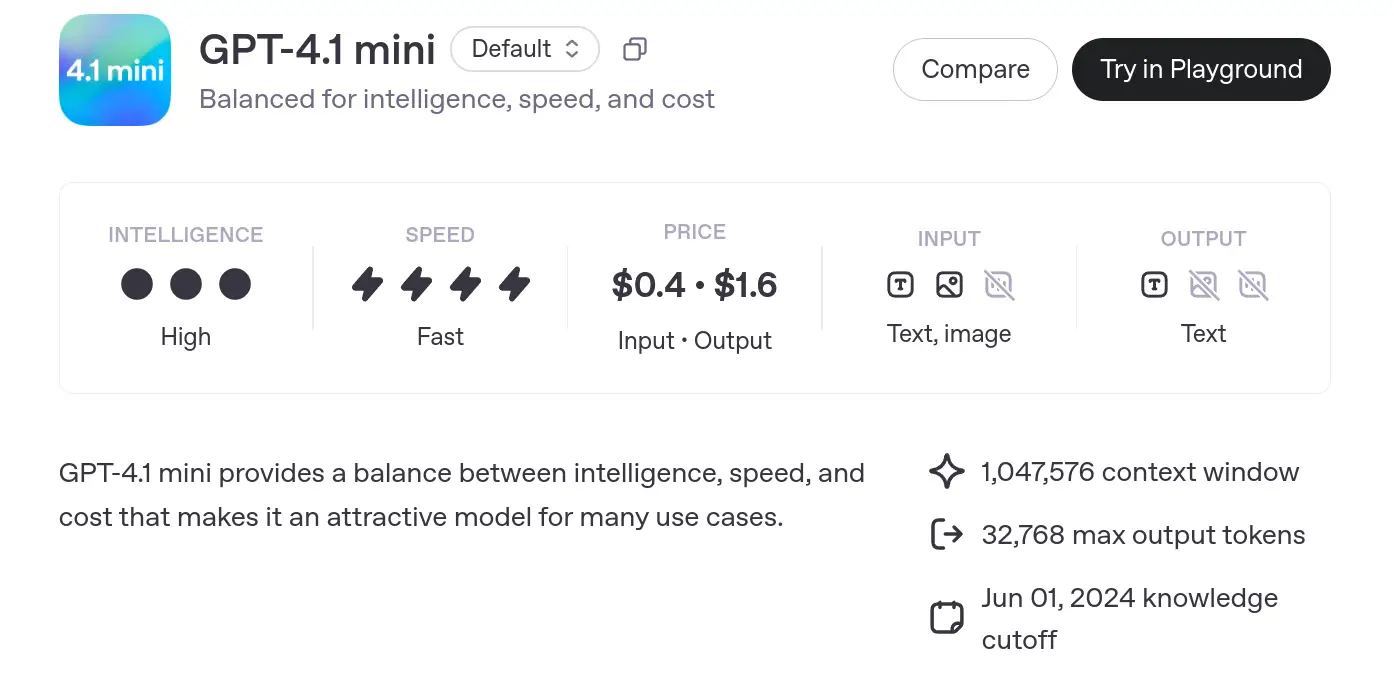
- The GPT-4.1 mini model is designed to balance intelligence, speed, and cost. It offers high intelligence and fast speed, making it suitable for many use cases.
- Pricing: $0.4 – $1.6 per input-output.
- Input: Text and image.
- Output: Text.
- Context Window: 1,047,576 tokens (large capacity for processing).
- Max Output: 32,768 tokens.
- Knowledge Cutoff: June 1, 2024.
Read this article to know more: All About OpenAI’s Latest GPT 4.1 Family
Building Agentic RAG Using GPT 4.1 mini
I am building a multi-document, agentic RAG system with GPT 4.1 mini. Here’s the workflow.
- Ingests two long PDFs (on ML and GenAI economics).
- Chunks them into overlapping pieces (chunk_size=5000, chunk_overlap=300)—designed to preserve context.
- Embeds these chunks using OpenAI’s text-embedding-3-small model.
- Stores them in two separate Chroma vector stores for efficient similarity-based retrieval.
- Wraps the retrieval+LLM prompt logic into two chains (one per topic).
- Exposes these chains as tools to a LangChain Zero-Shot Agent, which routes the query to the right context.
- Queries like “Why is Self-Attention used?” or “How will marketing change with GenAI?” are answered accurately and contextually—thanks to the big chunks and high-quality retrieval.
1. Setup and Installation
!pip install langchain==0.3.23
!pip install -U langchain-openai
!pip install langchain-community==0.3.11
!pip install langchain-chroma==0.1.4
!pip install pypdfInstall the necessary imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain.agents import AgentType, Tool, initialize_agentI am pinning specific versions of LangChain packages and related dependencies for compatibility—smart move.
2. OpenAI API Key
from getpass import getpass
OPENAI_KEY = getpass('Enter Open AI API Key: ')
import os
os.environ['OPENAI_API_KEY'] = OPENAI_KEY3. Load PDFs using PyPDFLoader
pdf_dir = "/content/document_pdf"
machinelearning_paper = os.path.join(pdf_dir, "Machinelearningalgorithm.pdf")
genai_paper = os.path.join(pdf_dir, "the-economic-potential-of-generative-ai-
the-next-productivity-frontier.pdf")
# Load individual PDF documents
print("Loading ml pdf...")
ml_loader = PyPDFLoader(machinelearning_paper)
ml_documents = ml_loader.load()
print("Loading genai pdf...")
genai_loader = PyPDFLoader(genai_paper)
genai_documents = genai_loader.load()Loads the PDFs into LangChain Document objects. Each page becomes one Document.
3. Chunk with RecursiveCharacterTextSplitter
# Split the documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=5000, chunk_overlap=300)
ml_splits = text_splitter.split_documents(ml_documents)
genai_splits = text_splitter.split_documents(genai_documents)
print(f"Created {len(ml_splits)} splits for ml PDF")
print(f"Created {len(genai_splits)} splits for genai PDF")This is the heart of your long-context handling. This tool:
- Keeps chunks under 5000 tokens.
- Preserves context with 300 overlap.
The recursive splitter tries splitting on paragraphs → sentences → characters, preserving as much semantic structure as possible.
Ml_splits[:3]

genai_splits[:5]

4. Embedding with OpenAIEmbeddings
# details here: https://openai.com/blog/new-embedding-models-and-api-updates
openai_embed_model = OpenAIEmbeddings(model="text-embedding-3-small")I am using the 2024 text-embedding-3-small model, which is:
- Smaller, faster, yet more accurate than older models.
- Great for cost-effective, high-quality retrieval.
5. Store in Chroma Vector Stores
# Create separate vectorstores
ml_vectorstore = Chroma.from_documents(
documents=ml_splits,
embedding=openai_embed_model,
collection_metadata={"hnsw:space": "cosine"},
collection_name="ml-knowledge"
)
genai_vectorstore = Chroma.from_documents(
documents=genai_splits,
embedding=openai_embed_model,
collection_metadata={"hnsw:space": "cosine"},
collection_name="genai-knowledge"
)Here, I am creating two vector stores:
- One for ML-related chunks
- One for GenAI-related chunks
Using cosine similarity for retrieval:
ml_retriever = ml_vectorstore.as_retriever(search_type="similarity_score_threshold",search_kwargs={"k": 5,"score_threshold": 0.3})
genai_retriever = genai_vectorstore.as_retriever(search_type="similarity_score_threshold",search_kwargs={"k": 5,"score_threshold": 0.3})Only return the top 5 chunks with enough similarity. Keeps answers tight.
query = "what are ML algorithms?"
top3_docs = ml_retriever.invoke(query)
top3_docs
6. Retrieval and Prompt Creation
# Create the prompt templates
ml_prompt = ChatPromptTemplate.from_template(
"""
You are an expert in machine learning algorithms with deep technical knowledge of the field.
Answer the following question based solely on the provided context extracted from relevant machine learning research documents.
Context:
{context}
Question:
{question}
If the answer cannot be found in the context, please respond with: "I don't have enough information to answer this question based on the provided context."
"""
)
genai_prompt = ChatPromptTemplate.from_template(
"""
You are an expert in the economic impact and potential of generative AI technologies across industries and markets.
Answer the following question based only on the provided context related to the economic aspects of generative AI.
Context:
{context}
Question:
{question}
If the answer cannot be found in the context, please state "I don't have enough information to answer this question based on the provided context."
"""
)Here, I am creating context-specific prompts:
- ML QA system: asks about algorithms, training, etc.
- GenAI QA system: focuses on economic impact, cross-industry uses.
These prompts also guard against hallucination with:
“If the answer cannot be found in the context… respond with: ‘I don’t have enough information…’”
Perfect for reliability.
7. LCEL Chains
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-4.1-mini-2025-04-14", temperature=0)def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)# Create the RAG chains using LCEL
ml_chain = (
{
"context": lambda question: format_docs(ml_retriever.get_relevant_documents(question)),
"question": RunnablePassthrough()
}
| ml_prompt
| llm
| StrOutputParser()
)
genai_chain = (
{
"context": lambda question: format_docs(genai_retriever.get_relevant_documents(question)),
"question": RunnablePassthrough()
}
| genai_prompt
| llm
| StrOutputParser()
)This is where LangChain Expression Language (LCEL) shines.
- Retrieve chunks
- Format them as context
- Inject into the prompt
- Send to gpt-4.1-mini
- Parse the response string
It’s elegant, reusable, and modular.
8. Define Tools for Agent
# Define the tools
tools = [
Tool(
name="ML Knowledge QA System",
func=ml_chain.invoke,
description="Useful for when you need to answer questions related to machine learning concepts, models, training techniques, evaluation metrics, algorithms and practical implementations. Covers supervised and unsupervised learning, model optimization, bias-variance tradeoff, feature engineering, and algorithm selection. Input should be a fully formed question."
),
Tool(
name="GenAI QA System",
func=genai_chain.invoke,
description="Useful for when you need to answer questions about the economic impact, market potential, and cross-industry implications of generative AI technologies. Input should be a fully formed question. Responses are based strictly on the provided context related to the economics of generative AI."
)
]Each chain becomes a Tool in LangChain. Tools are like plug-and-play capabilities for the agent.
9. Initialize Agent
# Initialize the agent
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)I am using the Zero-Shot ReAct agent, which interprets the query, decides which tool (ML or GenAI) to use, and routes the input accordingly.
10. Query Time!
result = agent.invoke("How marketing and sale could be transformed using Generative AI?")
Agent:
- Chooses GenAI QA System
- Retrieves top context chunks from GenAI vectorstore
- Formats prompt
- Sends to GPT-4.1
- Returns a grounded, non-hallucinated answer
result1 = agent.invoke("why Self-Attention is used?")
Agent:
- Chooses ML QA System
- Retrieves top context chunks from ML vectorstore
- Formats prompt
- Sends to GPT-4.1mini
- Returns a grounded, non-hallucinated answer
result2 = agent.invoke("what are Tree-based algorithms?")
GPT-4.1 proves to be exceptionally effective for working with large documents, thanks to its extended context window of up to 1 million tokens. This enhancement eliminates the long-standing limitations faced with previous models, where documents had to be heavily chunked into small segments, often losing semantic coherence.
With the ability to handle large chunks, such as the 5000-token segments used here, GPT-4.1 can ingest and reason over dense, information-rich sections without missing contextual links across paragraphs or pages. This is especially valuable in scenarios involving complex documents like academic papers or industry whitepapers, where understanding often depends on multi-page continuity. The model handles these extended chunks accurately and delivers context-grounded responses without hallucinations, a capability further amplified by well-designed retrieval prompts.
Moreover, in a RAG pipeline, the quality of responses is heavily tied to how much useful context the model can consume at once. GPT-4.1 removes the previous ceiling, making it possible to retrieve and reason over complete conceptual units rather than fragmented excerpts. As a result, you can ask deep, nuanced questions about long documents and receive precise, well-informed answers, making GPT-4.1 a game-changer for production-grade document analysis and retrieval-based applications.
Also read: A Comprehensive Guide to Building Agentic RAG Systems with LangGraph
More Than Just a “Needle in a Haystack”
This is a needle-in-a-haystack benchmark evaluating how well different models can retrieve or reason over a relevant piece of information (a “needle”) buried within a long context (“haystack”).
GPT-4.1 excels at finding specific facts in large documents, but OpenAI pushed things further with the OpenAI-MRCR benchmark, which tests multi-fact retrieval:
- With 2 key facts (“needles”): GPT-4.1 does better than 4.0.
- With 4 or more: Larger models like GPT-4.5 still dominate, especially in shorter input scenarios.
8-needle scenario – meaning 8 relevant pieces of information are embedded in a longer sequence of tokens, and the model is tested on its ability to retrieve or reference them accurately.
So, while GPT-4.1 handles basic long-context tasks well, it’s not quite ready for deep, interconnected reasoning yet.
2 Needle
This typically refers to a simpler version of the task, possibly with fewer categories or simpler decision points. The “accuracy” in this case is measured by how well the model performs when distinguishing between two categories or making two distinct decisions.

4 Needle
This would involve a more complex task where there are four distinct categories or outcomes to predict. It’s a more challenging task for the model compared to “2 needle,” meaning the model has to make more nuanced distinctions.

8 Needle
An even more complex scenario, where the model has to correctly predict from eight different categories or outcomes. The higher the “needle” count, the more challenging the task is, requiring the model to demonstrate a broader range of understanding and accuracy.

Still, depending on your use case (especially if you’re working with under 200K tokens), alternatives like DeepSeek-R1 or Gemini 2.5 might give you more value per dollar.
However, if your needs include cutting-edge reasoning or the most up-to-date knowledge, watch GPT-4.5 or competitors like Gemini.
GPT-4.1 may not be a total game-changer, but it’s a smart evolution, especially for developers. OpenAI focused on practical improvements: better coding support, long context processing, and lower costs to make the models more accessible.
Still, areas like benchmark transparency and knowledge freshness leave space for rivals to leap in. As competition ramps up, GPT-4.1 proves OpenAI is listening—now it’s Google, Anthropic, and the rest’s move.
Why Chunking Works So Well (5000 + 300 overlap)?
The config:
- chunk_size = 5000
- chunk_overlap = 300
Why is this effective with GPT-4.1?
- GPT-4.1 supports 1M token context. Feeding longer chunks is finally useful now. Smaller chunks would’ve missed the semantic glue between ideas spread across paragraphs.
- 5000-token chunks ensure minimal semantic splitting, capturing large conceptual units like “Transformer architecture” or “economic implications of GenAI”.
- 300-token overlap helps preserve cross-chunk context, preventing cutoff issues.
That’s likely why you’re not seeing misses or hallucinations—you’re giving the LLM exactly the chunked context it needs.
Alright, let’s break this down with a step-by-step guide to building an agentic Retrieval-Augmented Generation (RAG) pipeline using GPT-4.1 and leveraging its 1 million token context window capability by chunking and indexing two large PDFs (50+ pages each) to retrieve accurate answers with zero hallucination.
Key Benefits and Considerations of GPT 4.1
- Enhanced Retrieval: Superior performance in single-fact retrieval but slightly lower effectiveness in complex, multi-information synthesis tasks compared to larger models like GPT-4.5.
- Cost-effectiveness: Particularly the Nano variant, ideal for budget-sensitive, high-throughput tasks.
- Developer-friendly: Ideal for coding applications, legal document analysis, and lengthy context tasks.
Conclusion
GPT-4.1 Mini emerges as a robust and cost-effective foundation for constructing agentic Retrieval-Augmented Generation (RAG) systems. Its support for a 1 million token context window allows for the ingestion of large, semantically rich document chunks, enhancing the model’s ability to provide contextually grounded and accurate responses.
GPT-4.1 Mini’s enhanced instruction-following capabilities, long-context handling, and affordability make it an excellent choice for developing sophisticated, production-grade RAG applications. Its design facilitates deep, nuanced interactions with extensive documents, positioning it as a valuable asset in the evolving landscape of AI-driven information retrieval.
Frequently Asked Questions
Larger chunks let GPT-4.1 “see” bigger ideas all at once—like explaining a whole recipe instead of just listing ingredients. Smaller chunks might split up connected ideas (like separating “why self-attention works” from “how it’s calculated”), making answers less accurate.
If you dump everything into one pile, the model might mix up answers about machine learning algorithms with economics reports. Separating them is like giving the AI two specialized brains: one for coding and one for business analysis.
Yep! It’s ~83% cheaper than GPT-4.0 for basic tasks, and the Nano variant is built for apps needing tons of queries on a budget (like chatbots for customer support). But if you’re doing ultra-complex tasks, bigger models like GPT-4.5 might still be worth the cost.
Totally. The 1 M-token context means you can feed it entire contracts or reports without losing the bigger picture. Just tweak the prompts to say, “You’re a legal expert analyzing clauses…” and it’ll adapt.
It’s way better at multilingual tasks than older versions! For coding, it understands mixed languages (like Python + SQL). For text, it supports common languages like Spanish or French—but for niche dialects, competitors like Gemini 2.5 might still edge it out.
While it’s great at finding single facts in long docs, asking it to connect 8+ hidden details (like solving a mystery novel) can trip it up. For deep analysis, pair it with a human, or maybe, wait for GPT-4.5!
Hi, I am Pankaj Singh Negi – Senior Content Editor | Passionate about storytelling and crafting compelling narratives that transform ideas into impactful content. I love reading about technology revolutionizing our lifestyle.
Login to continue reading and enjoy expert-curated content.

{kind=link}