

Faster, smarter, more responsive AI applications – that’s what your users expect. But when large language models (LLMs) are slow to respond, user experience suffers. Every millisecond counts.
With Cerebras’ high-speed inference endpoints, you can reduce latency, speed up model responses, and maintain quality at scale with models like Llama 3.1-70B. By following a few simple steps, you’ll be able to customize and deploy your own LLMs, giving you the control to optimize for both speed and quality.
In this blog, we’ll walk you through you how to:
- Set up Llama 3.1-70B in the DataRobot LLM Playground.
- Generate and apply an API key to leverage Cerebras for inference.
- Customize and deploy smarter, faster applications.
By the end, you’ll be ready to deploy LLMs that deliver speed, precision, and real-time responsiveness.
Prototype, customize, and test LLMs in one place
Prototyping and testing generative AI models often require a patchwork of disconnected tools. But with a unified, integrated environment for LLMs, retrieval techniques, and evaluation metrics, you can move from idea to working prototype faster and with fewer roadblocks.
This streamlined process means you can focus on building effective, high-impact AI applications without the hassle of piecing together tools from different platforms.
Let’s walk through a use case to see how you can leverage these capabilities to develop smarter, faster AI applications.
Use case: Speeding up LLM interference without sacrificing quality
Low latency is essential for building fast, responsive AI applications. But accelerated responses don’t have to come at the cost of quality.
The speed of Cerebras Inference outperforms other platforms, enabling developers to build applications that feel smooth, responsive, and intelligent.
When combined with an intuitive development experience, you can:
- Reduce LLM latency for faster user interactions.
- Experiment more efficiently with new models and workflows.
- Deploy applications that respond instantly to user actions.
The diagrams below show Cerebras’ performance on Llama 3.1-70B, illustrating faster response times and lower latency than other platforms. This enables rapid iteration during development and real-time performance in production.
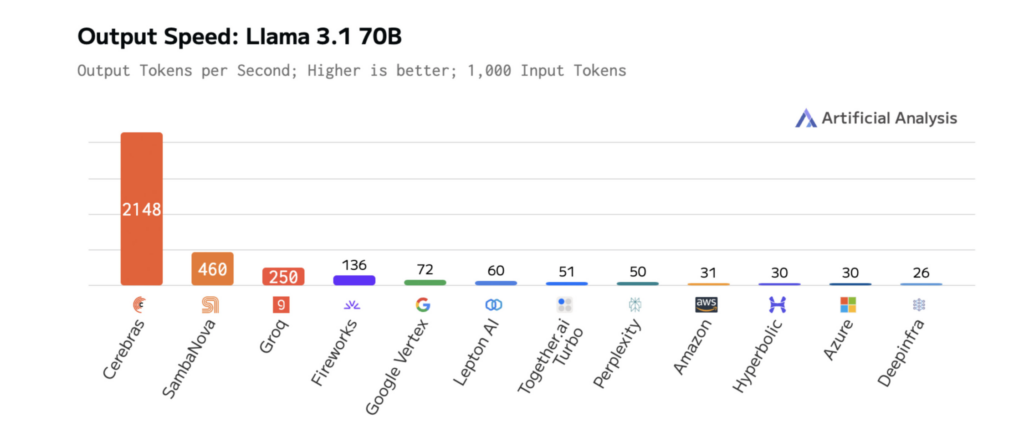
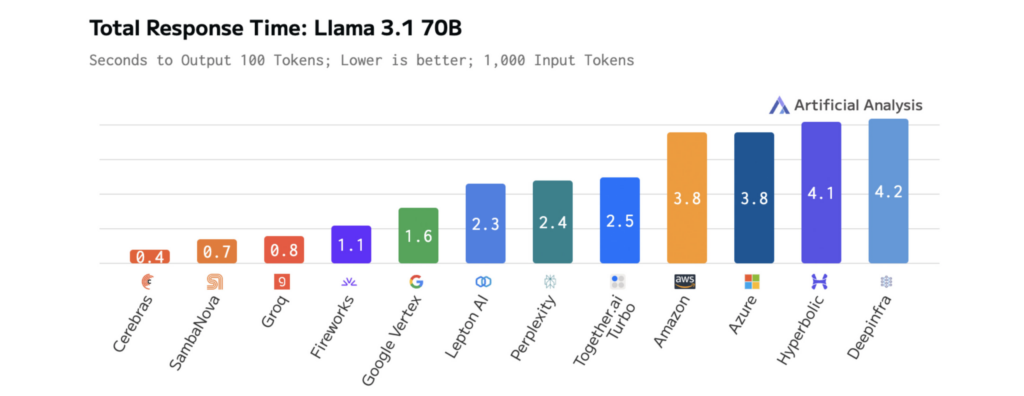
How model size impacts LLM speed and performance
As LLMs grow larger and more complex, their outputs become more relevant and comprehensive — but this comes at a cost: increased latency. Cerebras tackles this challenge with optimized computations, streamlined data transfer, and intelligent decoding designed for speed.
These speed improvements are already transforming AI applications in industries like pharmaceuticals and voice AI. For example:
- GlaxoSmithKline (GSK) uses Cerebras Inference to accelerate drug discovery, driving higher productivity.
- LiveKit has boosted the performance of ChatGPT’s voice mode pipeline, achieving faster response times than traditional inference solutions.
The results are measurable. On Llama 3.1-70B, Cerebras delivers 70x faster inference than vanilla GPUs, enabling smoother, real-time interactions and faster experimentation cycles.
This performance is powered by Cerebras’ third-generation Wafer-Scale Engine (WSE-3), a custom processor designed to optimize the tensor-based, sparse linear algebra operations that drive LLM inference.
By prioritizing performance, efficiency, and flexibility, the WSE-3 ensures faster, more consistent results during model performance.
Cerebras Inference’s speed reduces the latency of AI applications powered by their models, enabling deeper reasoning and more responsive user experiences. Accessing these optimized models is simple — they’re hosted on Cerebras and accessible via a single endpoint, so you can start leveraging them with minimal setup.

Step-by-step: How to customize and deploy Llama 3.1-70B for low-latency AI
Integrating LLMs like Llama 3.1-70B from Cerebras into DataRobot allows you to customize, test, and deploy AI models in just a few steps. This process supports faster development, interactive testing, and greater control over LLM customization.
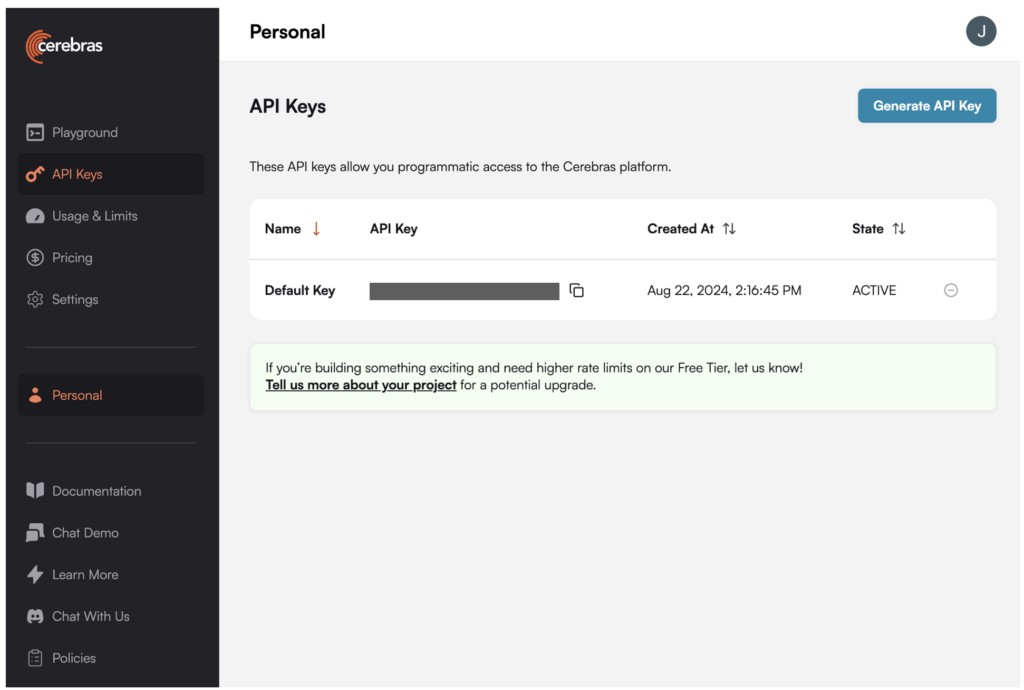
1. Generate an API key for Llama 3.1-70B in the Cerebras platform.
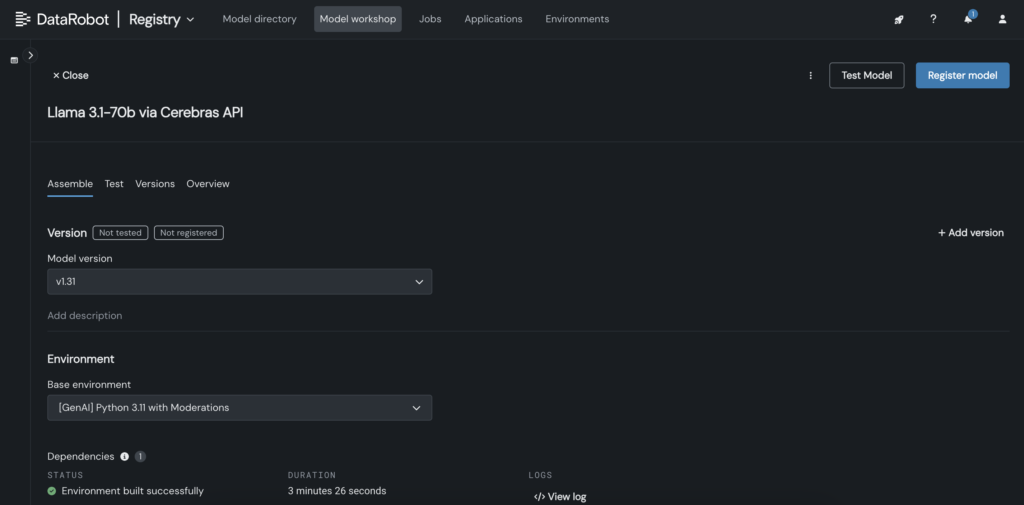
2. In DataRobot, create a custom model in the Model Workshop that calls out to the Cerebras endpoint where Llama 3.1 70B is hosted.
3. Within the custom model, place the Cerebras API key within the custom.py file.
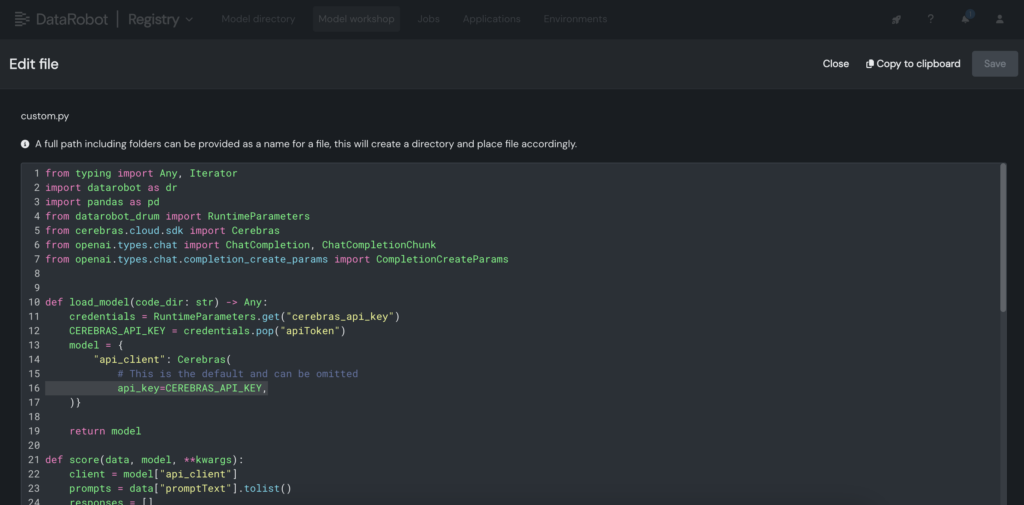
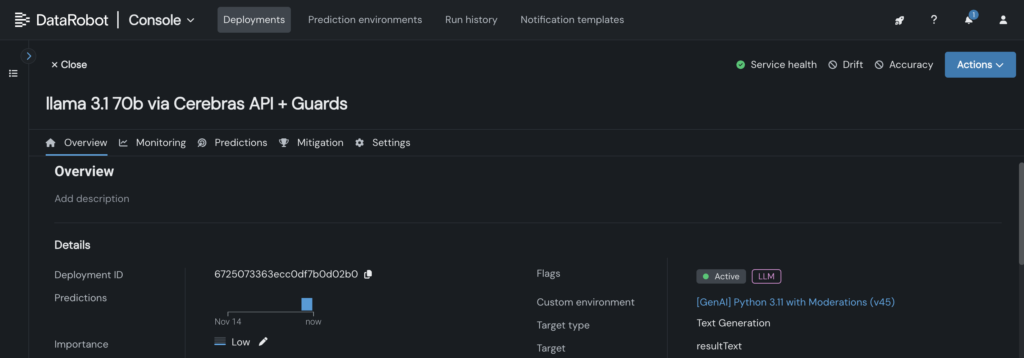
4. Deploy the custom model to an endpoint in the DataRobot Console, enabling LLM blueprints to leverage it for inference.
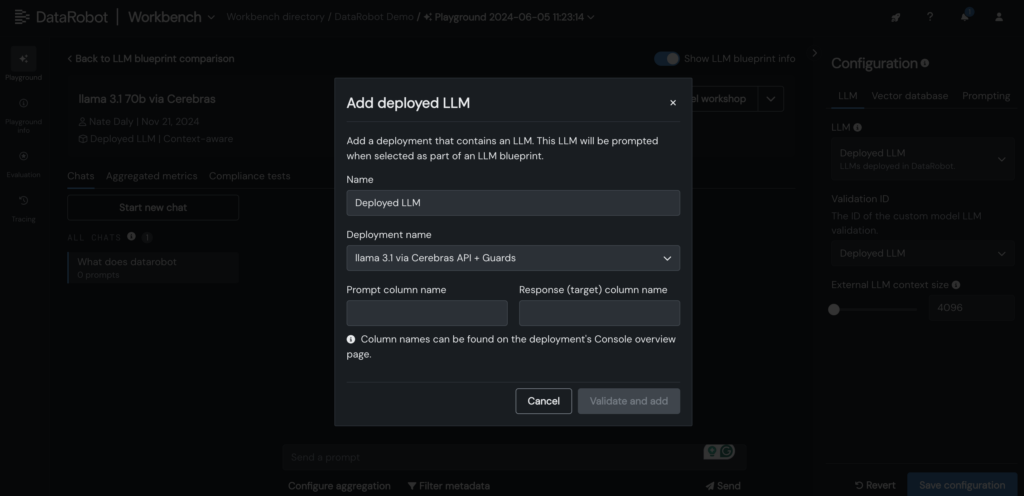
5. Add your deployed Cerebras LLM to the LLM blueprint in the DataRobot LLM Playground to start chatting with Llama 3.1 -70B.
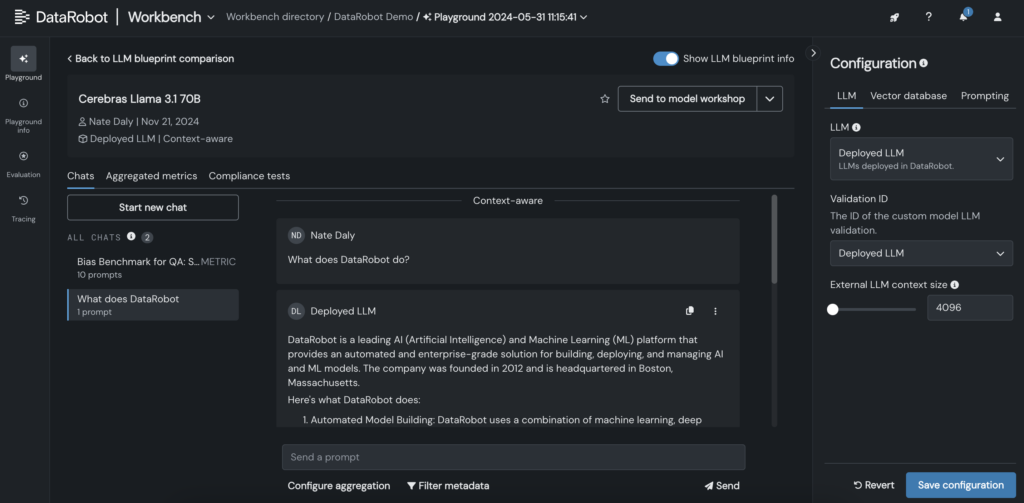
6. Once the LLM is added to the blueprint, test responses by adjusting prompting and retrieval parameters, and compare outputs with other LLMs directly in the DataRobot GUI.
Expand the limits of LLM inference for your AI applications
Deploying LLMs like Llama 3.1-70B with low latency and real-time responsiveness is no small task. But with the right tools and workflows, you can achieve both.
By integrating LLMs into DataRobot’s LLM Playground and leveraging Cerebras’ optimized inference, you can simplify customization, speed up testing, and reduce complexity – all while maintaining the performance your users expect.
As LLMs grow larger and more powerful, having a streamlined process for testing, customization, and integration, will be essential for teams looking to stay ahead.
Explore it yourself. Access Cerebras Inference, generate your API key, and start building AI applications in DataRobot.
About the author

Kumar Venkateswar is VP of Product, Platform and Ecosystem at DataRobot. He leads product management for DataRobot’s foundational services and ecosystem partnerships, bridging the gaps between efficient infrastructure and integrations that maximize AI outcomes. Prior to DataRobot, Kumar worked at Amazon and Microsoft, including leading product management teams for Amazon SageMaker and Amazon Q Business.

Nathaniel Daly is a Senior Product Manager at DataRobot focusing on AutoML and time series products. He’s focused on bringing advances in data science to users such that they can leverage this value to solve real world business problems. He holds a degree in Mathematics from University of California, Berkeley.

{kind=link}