


Welcome to the first installment of a series of posts discussing the recently announced Cloudera AI Inference service.
Today, Artificial Intelligence (AI) and Machine Learning (ML) are more crucial than ever for organizations to turn data into a competitive advantage. To unlock the full potential of AI, however, businesses need to deploy models and AI applications at scale, in real-time, and with low latency and high throughput. This is where the Cloudera AI Inference service comes in. It is a powerful deployment environment that enables you to integrate and deploy generative AI (GenAI) and predictive models into your production environments, incorporating Cloudera’s enterprise-grade security, privacy, and data governance.
Over the next several weeks, we’ll explore the Cloudera AI Inference service in-depth, providing you with a comprehensive introduction to its capabilities, benefits, and use cases.
In this series, we’ll delve into topics such as:
- A Cloudera AI Inference service architecture deep dive
- Key features and benefits of the service, and how it complements Cloudera AI Workbench
- Service configuration and sizing of model deployments based on projected workloads
- How to implement a Retrieval-Augmented Generation (RAG) system using the service
- Exploring different use cases for which the service is a great choice
If you’re interested in unlocking the full potential of AI and ML in your organization, stay tuned for our next posts, where we’ll dig deeper into the world of Cloudera AI Inference.
What is the Cloudera AI Inference service?
The Cloudera AI Inference service is a highly scalable, secure, and high-performance deployment environment for serving production AI models and related applications. The service is targeted at the production-serving end of the MLOPs/LLMOPs pipeline, as shown in the following diagram:
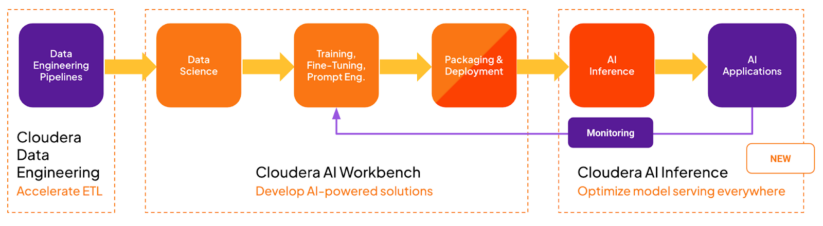
It complements Cloudera AI Workbench (previously known as Cloudera Machine Learning Workspace), a deployment environment that is more focused on the exploration, development, and testing phases of the MLOPs workflow.
Why did we build it?
The emergence of GenAI, sparked by the release of ChatGPT, has facilitated the broad availability of high-quality, open-source large language models (LLMs). Services like Hugging Face and the ONNX Model Zoo made it easy to access a wide range of pre-trained models. This availability highlights the need for a robust service that enables customers to seamlessly integrate and deploy pre-trained models from various sources into production environments. To meet the needs of our customers, the service must be highly:
- Secure – strong authentication and authorization, private, and safe
- Scalable – hundreds of models and applications with autoscaling capability
- Reliable – minimalist, fast recovery from failures
- Manageable – easy to operate, rolling updates
- Standards compliant – adopt market-leading API standards and model frameworks
- Resource efficient – fine-grained resource controls and scale to zero
- Observable – monitor system and model performance
- Performant – best-in-class latency, throughput, and concurrency
- Isolated – avoid noisy neighbors to provide strong service SLAs
These and other considerations led us to create the Cloudera AI Inference service as a new, purpose-built service for hosting all production AI models and related applications. It is ideal for deploying always-on AI models and applications that serve business-critical use cases.
High-level architecture
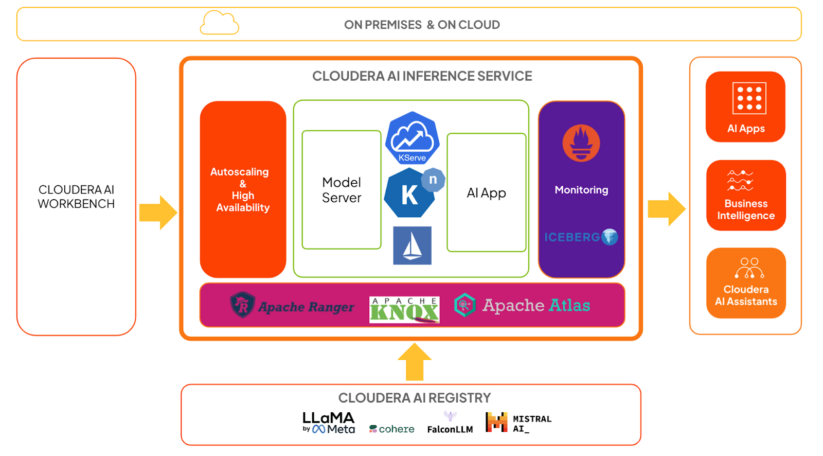
The diagram above shows a high-level architecture of Cloudera AI Inference service in context:
- KServe and Knative handle model and application orchestration, respectively. Knative provides the framework for autoscaling, including scale to zero.
- Model servers are responsible for running models using highly optimized frameworks, which we will cover in detail in a later post.
- Istio provides the service mesh, and we take advantage of its extension capabilities to add strong authentication and authorization with Apache Knox and Apache Ranger.
- Inference request and response payloads ship asynchronously to Apache Iceberg tables. Teams can analyze the data using any BI tool for model monitoring and governance purposes.
- System metrics, such as inference latency and throughput, are available as Prometheus metrics. Data teams can use any metrics dashboarding tool to monitor these.
- Users can train and/or fine-tune models in the AI Workbench, and deploy them to the Cloudera AI Inference service for production use cases.
- Users can deploy trained models, including GenAI models or predictive deep learning models, directly to the Cloudera AI Inference service.
- Models hosted on the Cloudera AI Inference service can easily integrate with AI applications, such as chatbots, virtual assistants, RAG pipelines, real-time and batch predictions, and more, all with standard protocols like the OpenAI API and the Open Inference Protocol.
- Users can manage all of their models and applications on the Cloudera AI Inference service with common CI/CD systems using Cloudera service accounts, also known as machine users.
- The service can efficiently orchestrate hundreds of models and applications and scale each deployment to hundreds of replicas dynamically, provided compute and networking resources are available.
Conclusion
In this first post, we introduced the Cloudera AI Inference service, explained why we built it, and took a high-level tour of its architecture. We also outlined many of its capabilities. We will dive deeper into the architecture in our next post, so please stay tuned.

{kind=link}