

Today, Confluent announced the general availability of its serverless Apache Flink service. Flink is one of the most popular stream processing technologies, ranked as a top five Apache project and backed by a diverse committer community including Alibaba and Apple. It powers steam processing at many companies including Uber, Netflix, and Linkedin.
Rockset customers using Flink often share how challenging it is to self-manage Flink for streaming transformations. That’s why we’re thrilled that Confluent Cloud is making it easier to use Flink, providing efficient and performant stream processing while saving engineers from complex infrastructure management.
While it’s well-known that Flink excels at filtering, joining and enriching streaming data from Apache Kafka® or Confluent Cloud, what is less known is that it is increasingly becoming ingrained in the end-to-end stack for AI-powered applications. That’s because successfully deploying an AI application requires retrieval augmented generation or “RAG” pipelines, processing real-time data streams, chunking data, generating embeddings, storing embeddings and running vector search.
In this blog, we’ll discuss how RAG fits into the paradigm of real-time data processing and show an example product recommendation application using both Kafka and Flink on Confluent Cloud together with Rockset.
What is RAG?
LLMs like ChatGPT are trained on vast amounts of text data available up to a cutoff date. For instance, GPT-4’s cutoff date was April 2023, so it would not be aware of any events or developments happening beyond that point of time. Furthermore, while LLMs are trained on a large corpus of text data, they are not trained to the specifics of a domain, use case or possess internal company knowledge. This knowledge is what gives many applications their relevance, generating more accurate responses.
LLMs are also prone to hallucinations, or making up inaccurate responses. By grounding responses in retrieval information, LLMs can draw on reliable data for their response instead of solely relying on their pre-existing knowledge base.
Building a real-time, contextual and trustworthy knowledge base for AI applications revolves around RAG pipelines. These pipelines take contextual data and feed it into an LLM to improve the relevancy of a response. Let’s take a look at each step in a RAG pipeline in the context of building a product recommendation engine:
- Streaming data: An online product catalog like Amazon has data on different products like name, maker, description, price, user recommendations, etc. The online catalog expands as new items are added or updates are made such as new pricing, availability, recommendations and more.
- Chunking data: Chunking is breaking down large text files into more manageable segments to ensure the most relevant chunk of information is passed to the LLM. For an example product catalog, a chunk may be the concatenation of the product name, description and a single recommendation.
- Generating vector embeddings: Creating vector embeddings involves transforming chunks of text into numerical vectors. These vectors capture the underlying semantics and contextual relationships of the text in a multidimensional space.
- Indexing vectors: Indexing algorithms can help to search across billions of vectors quickly and efficiently. As the product catalog is constantly being added to, generating new embeddings and indexing them happens in real time.
- Vector search: Find the most relevant vectors based on the search query in millisecond response times. For example, a user may be browsing “Space Wars” in a product catalog and looking for other similar video game recommendations.
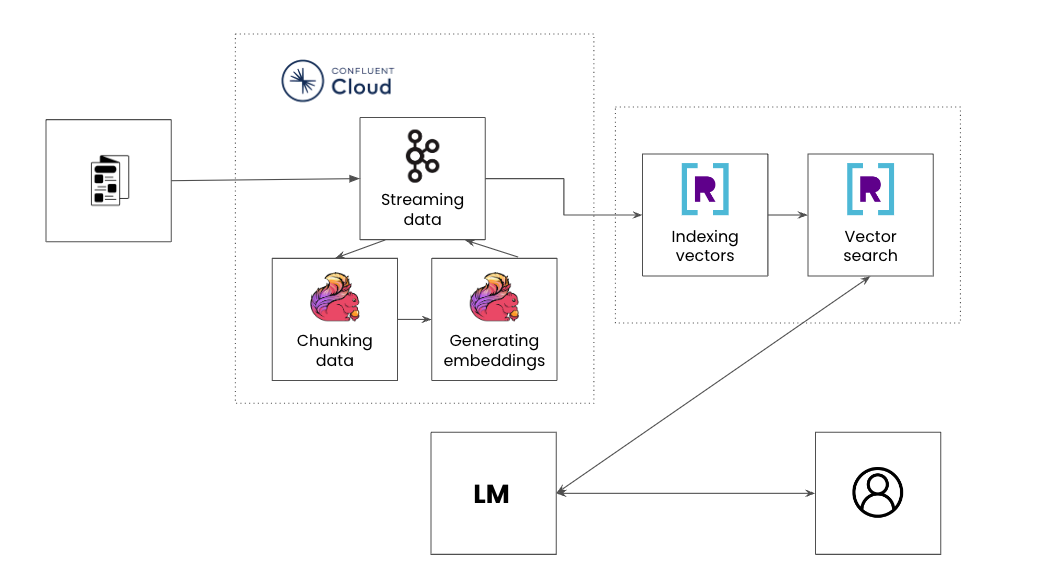

While a RAG pipeline captures the specific steps to build AI applications, these steps resemble a traditional stream processing pipeline where data is streamed from multiple sources, enriched and served to downstream applications. AI-powered applications also have the same set of requirements as any other user-facing application, its backend services need to be reliable, performant and scalable.
What are the challenges building RAG pipelines?
Streaming-first architectures are a necessary foundation for the AI era. A product recommendations application is much more relevant if it can incorporate signals about what products are in stock or can be shipped within 48 hours. When you are building applications for consistent, real-time performance at scale you will want to use a streaming-first architecture.
There are several challenges that emerge when building real-time RAG pipelines:
- Real-time delivery of embeddings & updates
- Real-time metadata filtering
- Scale and efficiency for real-time data
In the following sections, we’ll discuss these challenges broadly and delve into how they apply more specifically to vector search and vector databases.
Real-time delivery of embeddings and updates
Fast recommendations on fresh data require the RAG pipeline to be designed for streaming data. They also need to be designed for real-time updates. For a product catalog, the newest items need to have embeddings generated and added to the index.
Indexing algorithms for vectors do not natively support updates well. That’s because the indexing algorithms are carefully organized for fast lookups and attempts to incrementally update them with new vectors rapidly deteriorate the fast lookup properties. There are many potential approaches that a vector database can use to help with incremental updates- naive updating of vectors, periodic reindexing, etc. Each strategy has ramifications for how quickly new vectors can appear in search results.
Real-time metadata filtering
Streaming data on products in a catalog is used to generate vector embeddings as well as provide additional contextual information. For example, a product recommendation engine may want to show similar products to the last product a user searched (vector search) that are highly rated (structured search) and available for shipping with Prime (structured search). These additional inputs are referred to as metadata filtering.
Indexing algorithms are designed to be large, static and monolithic making it difficult to run queries that join vectors and metadata efficiently. The optimal approach is single-stage metadata filtering that merges filtering with vector lookups. Doing this effectively requires both the metadata and the vectors to be in the same database, leveraging query optimizations to drive fast response times. Almost all AI applications will want to include metadata, especially real-time metadata. How useful would your product recommendation engine be if the item recommended was out of stock?
Scale and efficiency for real-time data
AI applications can get very expensive very quickly. Generating vector embeddings and running vector indexing are both compute-intensive processes. The ability of the underlying architecture to support streaming data for predictable performance, as well as scale up and down on demand, will help engineers continue to leverage AI.
In many vector databases, indexing of vectors and search happen on the same compute clusters for faster data access. The downside of this tightly coupled architecture, often seen in systems like Elasticsearch, is that it can result in compute contention and provisioning of resources for peak capacity. Ideally, vector search and indexing happen in isolation while still accessing the same real-time dataset.
Why use Confluent Cloud for Apache Flink and Rockset for RAG?
Confluent Cloud for Apache Flink and Rockset, the search and analytics database built for the cloud, are designed to support high-velocity data, real-time processing and disaggregation for scalability and resilience to failures.
Here are the benefits of using Confluent Cloud for Apache Flink and Rockset for RAG pipelines:
- Support high-velocity stream processing and incremental updates: Incorporate real-time insights to improve the relevance of AI applications. Rockset is a mutable database, efficiently updating metadata and indexes in real time.
- Enrich your RAG pipeline with filters and joins: Use Flink to enrich the pipeline, generating real-time embeddings, chunking data and ensuring data security and privacy. Rockset treats metadata filtering as a first-class citizen, enabling SQL over vectors, text, JSON, geo and time series data.
- Build for scale and developer velocity: Scale up and down on demand with cloud-native services that are built for efficiency and elasticity. Rockset isolates indexing compute from query compute for predictable performance at scale.
Architecture for AI-powered Recommendations
Let’s now look at how we can leverage Kafka and Flink on Confluent Cloud with Rockset to build a real-time RAG pipeline for an AI-powered recommendations engine.
For this example AI-powered recommendation application, we’ll use a publicly available Amazon product reviews dataset that includes product reviews and associated metadata including product names, features, prices, categories and descriptions.

We’ll find the most similar video games to Starfield that are compatible with the Playstation console. Starfield is a popular video game on Xbox and gamers using Playstation may want to find similar games that work with their setup. We’ll use Kafka to stream product reviews, Flink to generate product embeddings and Rockset to index the embeddings and metadata for vector search.
Confluent Cloud
Confluent Cloud is a fully-managed data streaming platform that can stream vectors and metadata from wherever the source data resides, providing easy-to-use native connectors. Its managed service from the creators of Apache Kafka offers elastic scalability, guaranteed resiliency with a 99.99% uptime SLA and predictable low latency.
We setup a Kafka producer to publish events to a Kafka cluster. The producer ingests Amazon.com product catalog data in real time and sends it to Confluent Cloud. It runs java using docker compose to create the Kafka producer and Apache Flink.

In Confluent Cloud, we create a cluster for the AI-powered product recommendations with the topic of product.metadata.

Apache Flink for Confluent Coud
Easily filter, join and enrich the Confluent data stream with Flink, the de facto standard for stream processing, now available as a serverless, fully-managed solution on Confluent Cloud. Experience Kafka and Flink together as a unified platform, with fully integrated monitoring, security and governance.
To process the products.metadata and generate vector embeddings on the fly we use Flink on Confluent Cloud. During stream processing, each product review is consumed one-by-one, review text is extracted and sent to OpenAI to generate vector embeddings and vector embeddings are attached as events to a newly created products.embeddings topic. As we don’t have an embedding algorithm in-house for this example, we have to create a user-defined function to call out to OpenAI and generate the embeddings using self-managed Flink.

We can go back to the Confluent console and explore the products.embeddings topic created using Flink and OpenAI.

Rockset
Rockset is the search and analytics database built for the cloud with a native integration to Kafka for Confluent Cloud. With Rockset’s cloud-native architecture, indexing and vector search occur in isolation for efficient, predictable performance. Rockset is built on RocksDB and supports incremental updating of vector indexes efficiently. Its indexing algorithms are based on the FAISS library, a library that is well known for its support of updates.

Rockset acts as a sink for Confluent Cloud, picking up streaming data from the product.embeddings topic and indexing it for vector search.
At the time a search query is made, ie “find me all the similar embeddings to term “space wars” that are compatible with Playstation and below $50,” the application makes a call to OpenAI to turn the search term “space wars” into a vector embedding and then finds the most similar products in the Amazon catalog using Rockset as a vector database. Rockset uses SQL as its query language, making metadata filtering as easy as a SQL WHERE clause.

Cloud-native stack for AI-powered applications on streaming data
Confluent’s serverless Flink offering completes the end-to-end cloud stack for AI-powered applications. Engineering teams can now focus on building next generation AI applications rather than managing infrastructure. The underlying cloud services scale up and down on demand, guaranteeing predictable performance without the costly overprovisioning of resources.
As we walked through in this blog, RAG pipelines benefit from real-time streaming architectures, seeing improvements in the relevance and trustworthiness of AI applications. When designing for real-time RAG pipelines the underlying stack should support streaming data, updates and metadata filtering as first-class citizens.
Building AI-applications on streaming data has never been easier. We walked through the basics of building an AI-powered product recommendation engine in this blog. You can reproduce these steps using the code found in this GitHub repository. Get started building your own application today with free trials of Confluent Cloud and [Rockset].
Embedded content: https://youtu.be/mvkQjTIlc-c?si=qPGuMtCOzq9rUJHx
Note: The Amazon Review dataset was taken from: Justifying recommendations using distantly-labeled reviews and fine-grained aspects Jianmo Ni, Jiacheng Li, Julian McAuley Empirical Methods in Natural Language Processing (EMNLP), 2019. It contains actual products but they are a few years old

{kind=link}