
")
Overview
In this guide, you will:
- Gain a foundational understanding of RAG, its limitations and shortcomings
- Understand the idea behind Self-RAG and how it could lead to better LLM performance
- Learn how to utilize OpenAI API (GPT-4 model) with the Rockset API suite (vector database) along with LangChain to perform RAG (Retrieval-Augmented Generation) and create an end-to-end web application using Streamlit
- Find an end-to-end Colab notebook that you can run without any dependencies on your local operating system: RAG-Chatbot Workshop
Large Language Models and their Limitations
Large Language Models (LLMs) are trained on large datasets comprising text, images, or/and videos, and their scope is generally limited to the topics or information contained within the training data. Secondly, as LLMs are trained on datasets that are static and often outdated by the time they’re deployed, they are unable to provide accurate or relevant information about recent developments or trends. This limitation makes them unsuitable for scenarios where real-time up-to-the-minute information is critical, such as news reporting, etc.
As training LLMs is quite expensive, with models such as GPT-3 costing over $4.6 million, retraining the LLM is mostly not a feasible option to address these shortcomings. This explains why real-time scenarios, such as investigating the stock market or making recommendations, cannot depend on or utilize traditional LLMs.
Due to these aforementioned limitations, the Retrieval-Augmented Generation (RAG) approach was introduced to overcome the innate challenges of traditional LLMs.
What is RAG?
RAG (Retrieval-Augmented Generation) is an approach designed to enhance the responses and capabilities of traditional LLMs (Large Language Models). By integrating external knowledge sources with the LLM, RAG tackles the challenges of outdated, inaccurate, and hallucinated responses often observed in traditional LLMs.
How RAG Works
RAG extends the capabilities of an LLM beyond its initial training data by providing more accurate and up-to-date responses. When a prompt is given to the LLM, RAG first uses the prompt to pull relevant information from an external data source. The retrieved information, along with the initial prompt, is then passed to the LLM to generate an informed and accurate response. This process significantly reduces hallucinations that occur when the LLM has irrelevant or partially relevant information for a certain subject.
Advantages of RAG
- Enhanced Relevance: By incorporating retrieved documents, RAG can produce more accurate and contextually relevant responses.
- Improved Factual Accuracy: Leveraging external knowledge sources helps in reducing the likelihood of generating incorrect information.
- Flexibility: Can be applied to various tasks, including question answering, dialogue systems, and summarization.
Challenges of RAG
- Dependency on Retrieval Quality: The overall performance is heavily dependent on the quality of the retrieval step.
- Computational Complexity: Requires efficient retrieval mechanisms to handle large-scale datasets in real-time.
- Coverage Gaps: The combined external knowledge base and the model’s parametric knowledge might not always be sufficient to cover a specific topic, leading to potential model hallucinations.
- Unoptimized Prompts: Poorly designed prompts can result in mixed results from RAG.
- Irrelevant Retrieval: Instances where retrieved documents do not contain relevant information can fail to improve the model’s responses.
Considering these limitations, a more advanced approach called Self-Reflective Retrieval-Augmented Generation (Self-RAG) was developed.
What is Self-RAG?
Self-RAG builds on the principles of RAG by incorporating a self-reflection mechanism to further refine the retrieval process and enhance the language model’s responses.
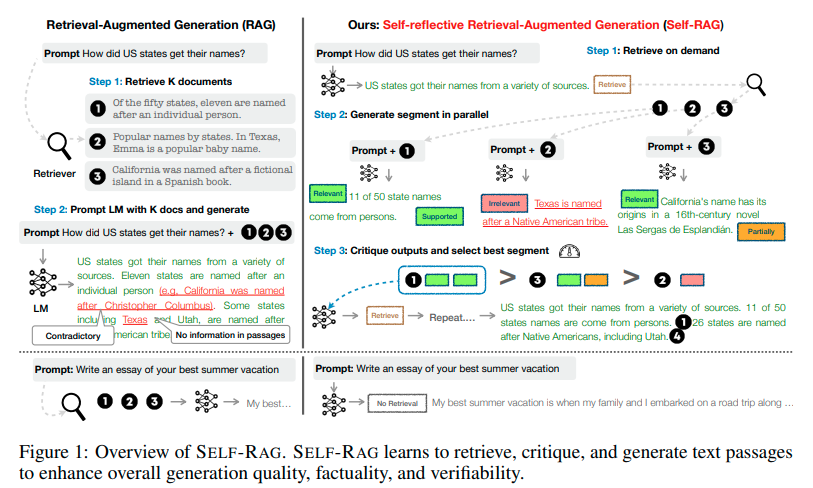
Key Features of Self-RAG
- Adaptive Retrieval: Unlike RAG’s fixed retrieval routine, Self-RAG uses retrieval tokens to assess the necessity of information retrieval. It dynamically determines whether to engage its retrieval module based on the specific needs of the input, intelligently deciding whether to retrieve multiple times or skip retrieval altogether.
- Intelligent Generation: If retrieval is needed, Self-RAG uses critique tokens like IsRelevant, IsSupported, and IsUseful to assess the utility of the retrieved documents, ensuring the generated responses are informed and accurate.
- Self-Critique: After generating a response, Self-RAG self-reflects to evaluate the overall utility and factual accuracy of the response. This step ensures that the final output is better structured, more accurate, and sufficient.
Advantages of Self-RAG
- Higher Quality Responses: Self-reflection allows the model to identify and correct its own mistakes, leading to more polished and accurate outputs.
- Continual Learning: The self-critique process helps the model to improve over time by learning from its own evaluations.
- Greater Autonomy: Reduces the need for human intervention in the refinement process, making it more efficient.
Comparison Summary
- Mechanism: Both RAG and Self-RAG use retrieval and generation, but Self-RAG adds a critique and refinement step.
- Performance: Self-RAG aims to produce higher quality responses by iteratively improving its outputs through self-reflection.
- Complexity: Self-RAG is more complex due to the additional self-reflection mechanism, which requires more computational power and advanced techniques.
- Use Cases: While both can be used in similar applications, Self-RAG is particularly beneficial for tasks requiring high accuracy and quality, such as complex question answering and detailed content generation.
By integrating self-reflection, Self-RAG takes the RAG framework a step further, aiming to enhance the quality and reliability of AI-generated content.
Overview of the Chatbot Application
In this tutorial, we will be implementing a chatbot powered with Retrieval Augmented Generation. In the interest of time, we will only utilize traditional RAG and observe the quality of responses generated by the model. We will keep the Self-RAG implementation and the comparisons between traditional RAG and self-RAG for a future workshop.
We’ll be generating embeddings for a PDF called Microsoft’s annual report in order to create an external knowledge base linked to our LLM to implement RAG architecture. Afterward, we’ll create a Query Lambda on Rockset that handles the vectorization of text representing the knowledge in the report and retrieval of the matched vectorized segment(s) of the document(s) in conjunction with the input user query. In this tutorial, we’ll be using GPT-4 as our LLM and implementing a function in Python to connect retrieved information with GPT-4 and generate responses.
Steps to build the RAG-Powered Chatbot using Rockset and OpenAI Embedding
Step 1: Generating Embeddings for a PDF File
The following code makes use of Openai’s embedding model along with Python’s ‘pypdf library to break the content of the PDF file into chunks and generate embeddings for these chunks. Finally, the text chunks are saved along with their embeddings in a JSON file for later.
from openai import OpenAI
import json
from pypdf import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
client = OpenAI(api_key="sk-************************")
def get_embedding(text):
response = client.embeddings.create(
input=[text],
model="text-embedding-3-small"
)
embedding = response.data[0].embedding
return embedding
reader = PdfReader("/content/microsoft_annual_report_2022.pdf")
pdf_texts = [p.extract_text().strip() for p in reader.pages if p.extract_text()]
character_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n"],
chunk_size=1000,
chunk_overlap=0
)
character_split_texts = character_splitter.split_text('\n\n'.join(pdf_texts))
data_for_json = []
for i, chunk in enumerate(character_split_texts, start=1):
embedding = get_embedding(chunk) # Use OpenAI API to generate embedding
data_for_json.append({
"chunk_id": str(i),
"text": chunk,
"embedding": embedding
})
# Writing the structured data to a JSON file
with open("chunks_with_embeddings.json", "w") as json_file:
json.dump(data_for_json, json_file, indent=4)
print(f"Total chunks: {len(character_split_texts)}")
print("Embeddings generated and stored in chunks_with_embeddings.json")
Step 2: Create a new Collection and Upload Data
To get started on Rockset, sign-up for free and get $300 in trial credits. After making the account, create a new collection from your Rockset console. Scroll to the bottom and choose File Upload under Sample Data to upload your data.

You’ll be directed to the following page. Click on Start.

Click on the file Upload button and navigate to the file you want to upload. We’ll be uploading the JSON file created in step 1 i.e. chunks_with_embeddings.json. Afterward, you’ll be able to review it under Source Preview.
Note: In practice, this data might come from a streaming service, a storage bucket in your cloud, or another connected service integrated with Rockset. Learn more about the connectors provided by Rockset here.

Now, you’ll be directed to the SQL transformation screen to perform transformations or feature engineering as per your needs.
As we don’t want to apply any transformation now, we’ll move on to the next step by clicking Next.

Now, the configuration screen will prompt you to choose your workspace along with the Collection Name and several other collection settings.
You should name the collection and then continue with default configurations by clicking Create.

Eventually, your collection will be set up. However, there may be a delay before the Ingest Status switches from Initializing to Connected.
After the status has been updated, you can use Rockset’s query tool to access the collection through the Query this Collection button located in the top-right corner of the image below.

Step 3: Generating Query Lambda on Rockset
Query lambda is a simple parameterized SQL query that is stored in Rockset so it can be executed from a dedicated REST endpoint and then utilized in various applications. In order to provide smooth information retrieval on the run to the LLM, we’ll configure the Query Lambda with the following query:
SELECT
chunk_id,
text,
embedding,
APPROX_DOT_PRODUCT(embedding, VECTOR_ENFORCE(:query_embedding, 1536, 'float')) as similarity
FROM
workshops.external_data d
ORDER BY similarity DESC
LIMIT :limit;
This parameterized query calculates the similarity using APPROXDOTPRODUCT between the embeddings of the PDF file and a query embedding provided as a parameter query_embedding.
We can find the most similar text chunks to a given query embedding with this query while allowing for efficient similarity search within the external data source.
To build this Query Lambda, query the collection made in step 2 by clicking on Query this collection and pasting the parameterized query above into the query editor.

Next, add the parameters one by one to run the query before saving it as a query lambda.


Click on Save in the query editor and name your query lambda to use it from endpoints later.

Whenever this query is executed, it will return the chunk_id, text, embedding, and similarity for each record, ordered by the similarity in descending order while the LIMIT clause will limit the total number of results returned.
If you’d like to know more about Query lambdas, feel free to read this blog post.
Step 4: Implementing RAG-based chatbot with Rockset Query Lambda
We’ll be implementing two functions retrieve_information and rag with the help of Openai and Rockset APIs. Let’s dive into these functions and understand their functionality.
- Retrieve_information
This function queries the Rockset database using an API key and a query embedding generated through Openai’s embedding model. The function connects to Rockset, executes a pre-defined query lambda created in step 2, and processes the results into a list object.
import rockset
from rockset import *
from rockset.models import *
rockset_key = os.environ.get('ROCKSET_API_KEY')
region = Regions.usw2a1
def retrieve_information( region, rockset_key, search_query_embedding):
print("\nRunning Rockset Queries...")
rs = RocksetClient(api_key=rockset_key, host=region)
api_response = rs.QueryLambdas.execute_query_lambda_by_tag(
workspace="workshops",
query_lambda="chatbot",
tag="latest",
parameters=[
{
"name": "embedding",
"type": "array",
"value": str(search_query_embedding)
}
]
)
records_list = []
for record in api_response["results"]:
record_data = {
"text": record['text']
}
records_list.append(record_data)
return records_list
- RAG
The rag function uses Openai’s chat.completions.create to generate a response where the system is instructed to act as a financial research assistant. The retrieved documents from retrieve_information are fed into the model along with the user’s original query. Finally, the model then generates a response that is contextually relevant to the input documents and the query thereby implementing an RAG flow.
from openai import OpenAI
client = OpenAI()
def rag(query, retrieved_documents, model="gpt-4-1106-preview"):
messages = [
{
"role": "system",
"content": "You are a helpful expert financial research assistant. You will be shown the user's question, and the relevant information from the annual report. Respond according to the provided information"
},
{"role": "user", "content": f"Question: {query}. \n Information: {retrieved_documents}"}
]
response = client.chat.completions.create(
model=model,
messages=messages,
)
content = response.choices[0].message.content
return content
Step 5: Setting Up Streamlit for Our Chatbot
To make our chatbot accessible, we’ll wrap the backend functionalities into a Streamlit application. Streamlit provides a hassle-free front-end interface, enabling users to input queries and receive responses directly through the web app.
The following code snippet will be used to create a web-based chatbot using Streamlit, Rockset, and OpenAI’s embedding model. Here’s a breakdown of its functionalities:
- Streamlit Tittle and Subheader: The code begins setting up the webpage configuration with the title “RockGPT” and a subheader that describes the chatbot as a “Retrieval Augmented Generation based Chatbot using Rockset and OpenAI“.
- User Input: It prompts users to input their query using a text input box labeled “Enter your query:“.
-
Submit Button and Processing:
- When the user presses the ‘Submit‘ button, the code checks if there is any user input.
- If there is input, it proceeds to generate an embedding for the query using OpenAI’s embeddings.create function.
- This embedding is then used to retrieve related documents from a Rockset database through the getrsresults function.
-
Response Generation and Display:
- Using the retrieved documents and the user’s query, a response is generated by the rag function.
- This response is then displayed on the webpage formatted as markdown under the header “Response:“.
- No Input Handling: If the Submit button is pressed without any user input, the webpage prompts the user to enter a query.
import streamlit as st
# Streamlit UI
st.set_page_config(page_title="RockGPT")
st.title("RockGPT")
st.subheader('Retrieval Augmented Generation based Chatbot using Rockset and OpenAI',divider="rainbow")
user_query = st.text_input("Enter your query:")
if st.button('Submit'):
if user_query:
# Generate an embedding for the user query
embedding_response = client.embeddings.create(input=user_query, model="text-embedding-3-small")
search_query_embedding = embedding_response.data[0].embedding
# Retrieve documents from Rockset based on the embedding
records_list = get_rs_results(region, rockset_key, search_query_embedding)
# Generate a response based on the retrieved documents
response = rag(user_query, records_list)
# Display the response as markdown
st.markdown("**Response:**")
st.markdown(response)
else:
st.markdown("Please enter a query to get a response.")
Here’s how our Streamlit application will initially appear in the browser:

Below is the complete code snippet for our Streamlit application, saved in a file named app.py. This script does the following:
- Initializes the OpenAI client and sets up the Rockset client using API keys.
- Defines functions to query Rockset with the embeddings generated by OpenAI, and to generate responses using the retrieved documents.
- Sets up a simple Streamlit UI where users can enter their query, submit it, and view the chatbot’s response.
import streamlit as st
import os
import rockset
from rockset import *
from rockset.models import *
from openai import OpenAI
# Initialize OpenAI client
client = OpenAI()
# Set your Rockset API key here or fetch from environment variables
rockset_key = os.environ.get('ROCKSET_API_KEY')
region = Regions.usw2a1
def get_rs_results(region, rockset_key, search_query_embedding):
"""
Query the Rockset database using the provided embedding.
"""
rs = RocksetClient(api_key=rockset_key, host=region)
api_response = rs.QueryLambdas.execute_query_lambda_by_tag(
workspace="workshops",
query_lambda="chatbot",
tag="latest",
parameters=[
{
"name": "embedding",
"type": "array",
"value": str(search_query_embedding)
}
]
)
records_list = []
for record in api_response["results"]:
record_data = {
"text": record['text']
}
records_list.append(record_data)
return records_list
def rag(query, retrieved_documents, model="gpt-4-1106-preview"):
"""
Generate a response using OpenAI's API based on the query and retrieved documents.
"""
messages = [
{"role": "system", "content": "You are a helpful expert financial research assistant. You will be shown the user's question, and the relevant information from the annual report. Respond according to the provided information."},
{"role": "user", "content": f"Question: {query}. \n Information: {retrieved_documents}"}
]
response = client.chat.completions.create(
model=model,
messages=messages,
)
return response.choices[0].message.content
# Streamlit UI
st.set_page_config(page_title="RockGPT")
st.title("RockGPT")
st.subheader('Retrieval Augmented Generation based Chatbot using Rockset and OpenAI',divider="rainbow")
user_query = st.text_input("Enter your query:")
if st.button('Submit'):
if user_query:
# Generate an embedding for the user query
embedding_response = client.embeddings.create(input=user_query, model="text-embedding-3-small")
search_query_embedding = embedding_response.data[0].embedding
# Retrieve documents from Rockset based on the embedding
records_list = get_rs_results(region, rockset_key, search_query_embedding)
# Generate a response based on the retrieved documents
response = rag(user_query, records_list)
# Display the response as markdown
st.markdown("**Response:**")
st.markdown(response)
else:
st.markdown("Please enter a query to get a response.")
Now that everything is configured, we can launch the Streamlit application and query the report using RAG, as shown in the picture below:

By following the steps outlined in this blog post, you’ve learned how to set up an intelligent chatbot or search assistant capable of understanding and responding effectively to your queries.
Don’t stop there—take your projects to the next level by exploring the wide range of applications possible with RAG, such as advanced question-answering systems, conversational agents and chatbots, information retrieval, legal research and analysis tools, content recommendation systems, and more.
Cheers!!!

{kind=link}