


(Dragon Claws/Shutterstock)
Last week’s GTC 2025 show may have been agentic AI’s breakout moment, but the core technology behind it has been quietly improving behind the scenes. That progress is being tracked across a series of coding benchmarks, such as SWE-bench and GAIA, leading some to believe AI agents are on the cusp of something big.
It wasn’t that long ago that AI-generated code was not deemed suitable for deployment. The SQL code would be too verbose or the Python code would be buggy or insecure. However, that situation has changed considerably in recent months, and AI models today are generating more code for customers every day.
Benchmarks provide a good way to gauge how far agentic AI has come in the software engineering domain. One of the more popular benchmarks, dubbed SWE-bench, was created by researchers at Princeton University to measure how well LLMs like Meta’s Llama and Anthropic’s Claude can solve common software engineering challenges. The benchmark utilizes GitHub as a rich resource of Python software bugs across 16 repositories, and provides a mechanism for measuring how well the LLM-based AI agents can solve them.
When the authors submitted their paperm, “SWE-Bench: Can Language Models Resolve Real-World GitHub Issues?” to the by the International Conference on Learning Representations (ICLR) in October 2023, the LLMs were not performing at a high level. “Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues,” the authors wrote in the abstract. “The best-performing model, Claude 2, is able to solve a mere 1.96% of the issues.”
That changed quickly. Today, the SWE-bench leaderboard shows the top-scoring model resolved 55% of the coding issues on SWE-bench Lite, which is a subset of the benchmark designed to make evaluation less costly and more accessible.
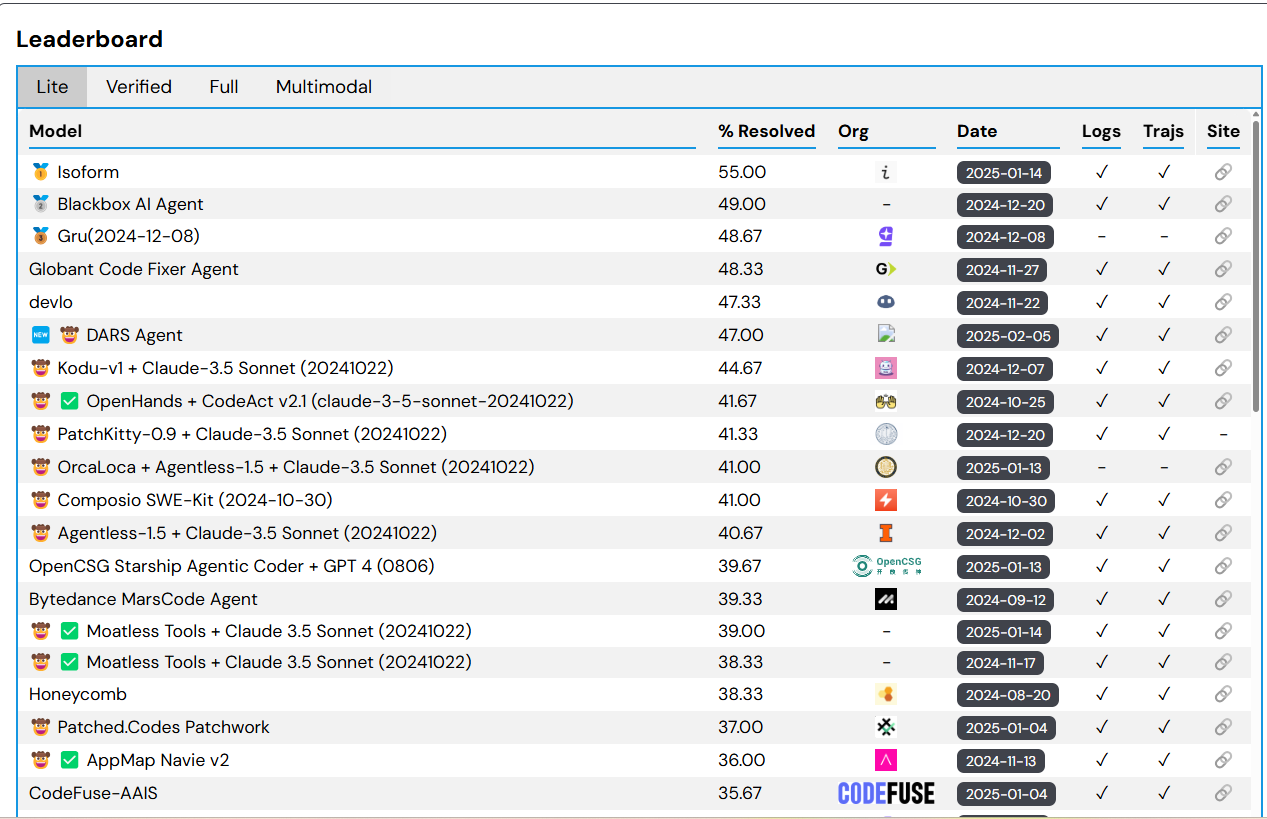
SWE-bench measures AI agents’ capabilites to resolve GitHub issues. You can see the current leaders at https://www.swebench.com/
Huggingface put together a benchmark for General AI Assistants, dubbed GAIA, that measures a model’s capability across several realms, including reasoning, multi-modality handling, Web browsing, and generally tool-use proficiency. The GAIA tests are non-ambiguous, and are challenging, such as counting the number of birds in a five-minute video.
A year ago, the top score on level 3 of the GAIA test was around 14, according to Sri Ambati, the CEO and co-founder of H2O.ai. Today, an H2O.ai-based model based on Claude 3.7 Sonnet holds the top overall score, about 53.
“So the accuracy is just really growing very fast,” Ambati said. “We’re not fully there, but we are on that path.”
H2O.ai’s software is involved in another benchmark that measures SQL generation. BIRD, which stands for BIg Bench for LaRge-scale Database Grounded Text-to-SQL Evaluation, measures how well AI models can parse natural language into SQL.
When BIRD debuted in May 2023, the top scoring model, CoT+ChatGPT, demonstrated about 40% accuracy. One year ago, the top scoring AI model, ExSL+granite-20b-code, was based on IBM’s Granite AI model and had an accuracy of about 68%. That was quite a bit below the capability of human performance, which BIRD measures at about 92%. The current BIRD leaderboard shows an H2O.ai-based model from AT&T as the leader, with an 77% accuracy rate.
The rapid progress in generating decent computer code has led some influential AI leaders, such as Nvidia CEO and co-founder Jensen Huang and Anthropic co-founder and CEO Dario Amodei, to make bold predictions about where we will soon find ourselves.
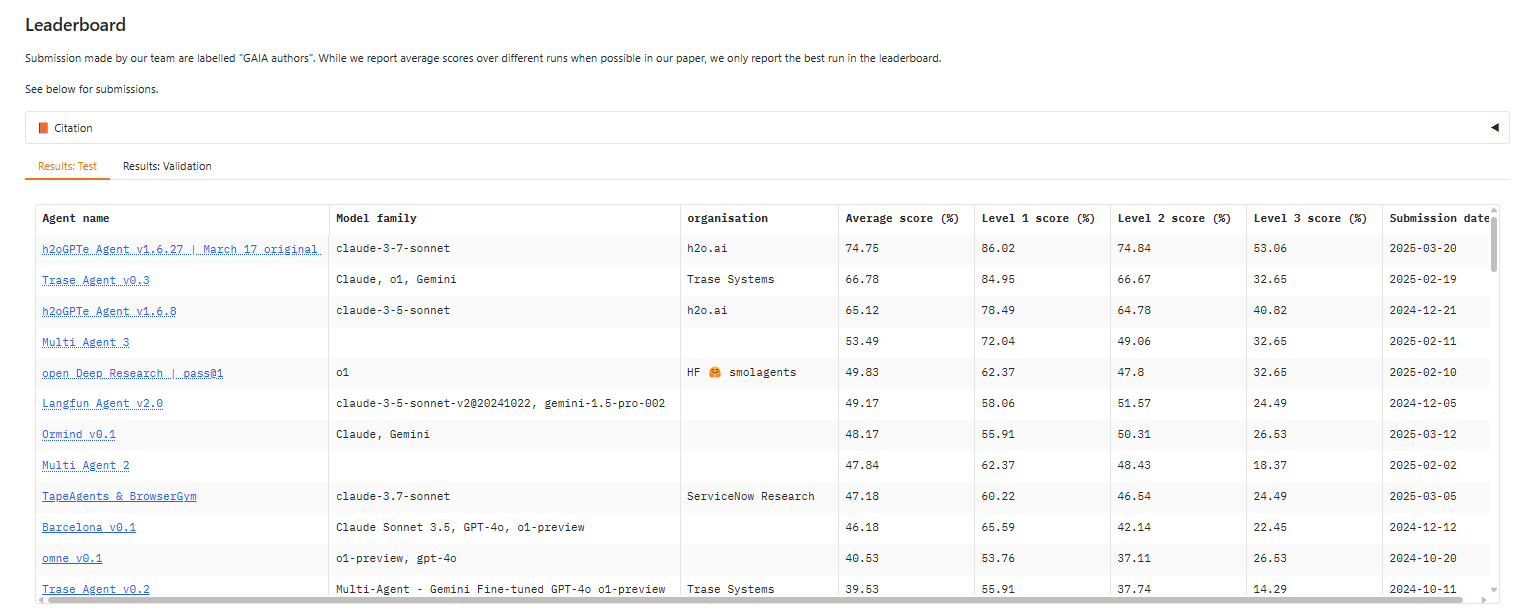
GAIA measures AI agents’ capability to handle a number of tasks. You can see the current leaders board at https://huggingface.co/spaces/gaia-benchmark/leaderboard
“We are not far from a world–I think we’ll be there in three to six months–where AI is writing 90 percent of the code,” Amodei said earlier this month. “And then in twelve months, we may be in a world where AI is writing essentially all of the code.”
During his GTC25 keynote last week, Huang shared his vision about the future of agentic computing. In his view, we are rapidly approaching a world where AI factories generate and run software based on human inputs, as opposed to humans writing software to retrieve and manipulate data.
“Whereas in the past we wrote the software and we ran it on computers, in the future, the computers are going to generate the tokens for the software,” Huang said. “And so the computer has become a generator of tokens, not a retrieval of files. [We’ve gone] from retrieval-based computing to generative-based computing.”
Others are taking a more pragmatic view. Anupam Datta, the principal research scientist at Snowflake and lead of the Snowflake AI Research Team, applauds the improvement in SQL generation. For instance, Snowflake says its Cortex Agent’s text-to-SQL generation accuracy rate is 92%. However, Datta doesn’t share Amodei’s view that computers will be rolling their own code by the end of the year.
“My view is that coding agents in certain areas, like text-to-SQL, I think are getting really good,” Datta said at GTC25 last week. “Certain other areas, they’re more assistants that help a programmer get faster. The human is not out of the loop just yet.”
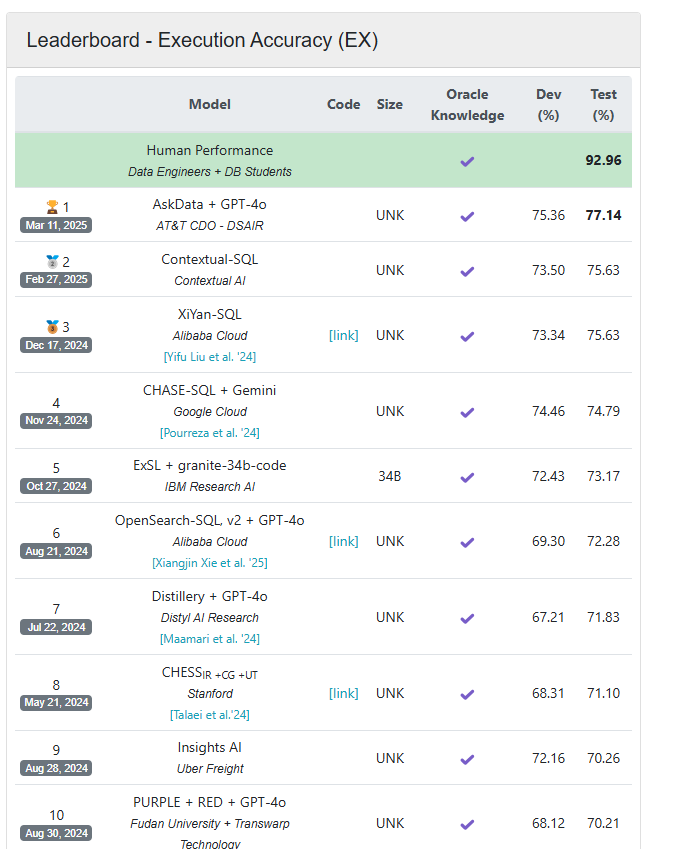
BIRD measures the text-to-SQL capability of AI agents. You can access the current leaderbord at https://bird-bench.github.io/
Programmer productivity will be the big winner thanks to coding copilots and agentic AI systems, he said. We’re not far from a world where agentic AI will generate the first draft, he said, and then the humans will come in and refine and improve it. “There will be huge gains in productivity,” Datta said. “So the impact will very significant, just with copilot alone.”
H2O.ai’s Ambati also believes that software engineers will work closely with AI. Even the best coding agents today introduce “subtle bugs,” so people still need to look at it the code, he said. “It’s still a pretty necessary skill set.”
One area that’s still pretty green is the semantic layer, where natural language is translated into business context. The problem is that the English language can be ambiguous, with multiple meanings from the same phrase.
“Part of it is understanding the semantics layer of the customer schema, the metadata,” Ambati said. “That piece is still building. That ontology is still a bit of a domain knowledge.”
Hallucinations are still an issue too, as is the potential for an AI model to go off the rails and say or do bad things. Those are all areas of concern that companies like Anthropic, Nvidia, H2O.ai, and Snowflake are all working to mitigate. But as the core capabilities of Gen AI get better, the number of reasons not to put AI agents into production decreases.
Related Items:
Accelerating Agentic AI Productivity with Enterprise Frameworks
Nvidia Preps for 100x Surge in Inference Workloads, Thanks to Reasoning AI Agents
Reporter’s Notebook: AI Hype and Glory at Nvidia GTC 2025

{kind=link}